Abstract
Gloss-free Sign Language Production (SLP) directly translates spoken language into sign poses, eschewing the needs for glosses. Glosses, essentially unique identifiers for individual signs, provide a direct link between spoken language and sign poses. However, they demand intricate annotations by SL experts and often miss the subtle intricacies of SL expressions, particularly the manual and non-manual signals [1,2].
This paper presents the Sign language Vector Quantization Network (SignVQNet), a novel approach to SLP that leverages Vector Quantization to derive discrete representations from sign pose sequences. Our method, rooted in both manual and non-manual elements of signing, supports advanced decoding methods and integrates latent-level alignment for enhanced linguistic coherence.
Through comprehensive evaluations, we demonstrate superior performance of our method over prior SLP methods and highlight the reliability of Back-Translation and Fréchet Gesture Distance as evaluation metrics.
Visual Comparison
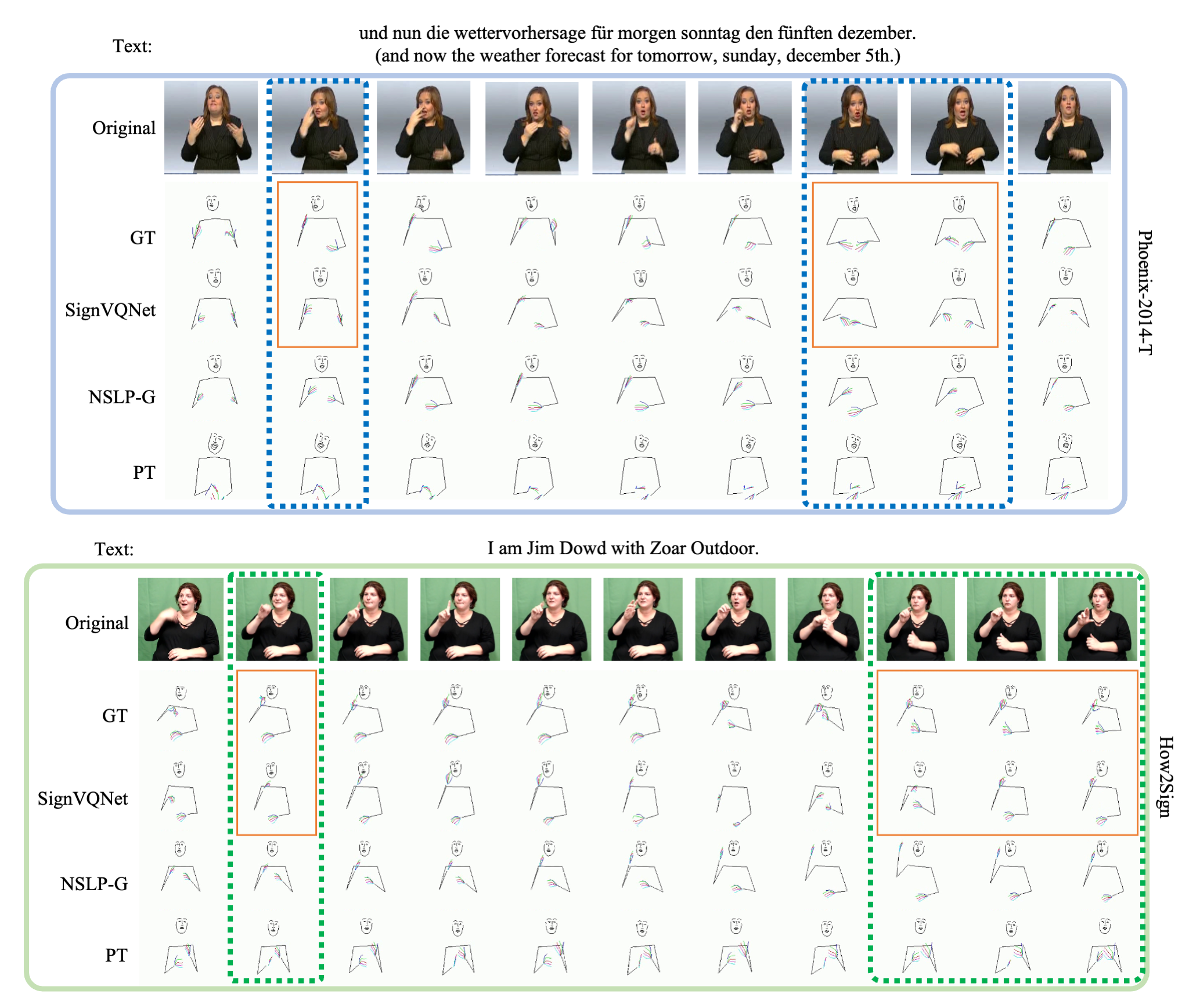
We present a visual comparison of the generated outputs from our approach against state-of-the-art baselines on both the PHOENIX-2014-T [3] and How2Sign [4] datasets. As highlighted within the dashed boxes, our approach shows better quality in terms of generating more realistic and accurate sign pose sequences.
It is important to emphasize the distinction in loss functions: while SignVQNet employs CE loss, both NSLP-G and PT utilize MSE loss, each tailored for specific objectives. SignVQNet is designed to predict the probability distribution of the subsequent sign pose, whereas NSLP-G and PT aim to precisely replicate the sign pose for each individual frame.
Consequently, SignVQNet might not always produce the exact sign pose for a specific frame. However, it effectively captures and conveys the overarching semantic essence of Sign Language.
Supplementary Video
For a more detailed visual representation, we provide supplementary video, which showcases the accurate depiction of words such as "now", "weather", "south", "coming", and "region".
Additional Discussion
Potential Societal Impact
The development and refinement of Gloss-free Sign Language Production (SLP) systems, such as SignVQNet, promise transformative changes for society, particularly for the deaf and hard-of-hearing community.
One of the most immediate impacts of SLP systems is their potential to enhance accessibility. By translating spoken language directly into sign poses without the intermediary of glosses, these systems can bridge the communication gap between the hearing and deaf communities. This breakthrough paves the way for more inclusive educational, professional, and social environments, ensuring that deaf and hard-of-hearing individuals are no longer sidelined.
The current reliance on Sign Language experts for intricate annotations is a bottleneck in expanding sign language translation. Efficient SLP systems, such as SignVQNet, can significantly reduce this dependency. This not only makes the process of generating sign language more scalable but also democratizes access, ensuring more people can benefit from these translations without waiting for expert interventions.
Limitations and Future Work
One limitation of our framework is its reduced emphasis on finger movements compared to arm movements. This challenge arises particularly with small-scale datasets due to the fingers' high degree of freedom and their nuanced movements, which result in low data variance. However, the recent introduction of large-scale SL datasets, such as NIASL21[5], presents a potential solution. Additionally, SignVQNet can learn sign poses in a language-independent manner, allowing it to be pre-trained on multiple datasets and potentially improving expression accuracy.
In future work, we aim to leverage multiple SL datasets to enhance our approach. Furthermore, we plan to synthesize sign videos or create avatar-based sign animations to produce more lifelike sign sequences.
References
[1] Mathias Muller, Zifan Jiang, Amit Moryossef, Annette and Sarah Ebling, "Considerations for meaningful sign language machine translation based on glosses," in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023, pp. 682–693.
[2] Kezhou Lin, Xiaohan Wang, Linchao Zhu, Ke Sun, Bang Zhang, and Yi Yang, "Gloss-free end-to-end sign language translation," in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023, pp. 12904–12916.
[3] Necati Cihan Camgoz, Simon Hadfield, Oscar Koller, Hermann Ney, and Richard Bowden, "Neural sign language translation," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7784–7793.
[4] Amanda Duarte, Shruti Palaskar, Lucas Ventura, Deepti Ghadiyaram, Kenneth DeHaan, Florian Metze, Jordi Torres, and Xavier Giro-i-Nieto, "How2sign: A large-scale multimodal dataset for continuous american sign language," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2735–2744.
[5] Mathew Huerta-Enochian, Du Hui Lee, Hye Jin Myung, Kang Suk Byun, and Jun Woo Lee. "Kosign sign language translation project: Introducing the niasl2021 dataset," in Proceedings of the 7th International Workshop on Sign Language Translation and Avatar Technology, European Language Resources Association, 2022, pp. 59–66.